
DeepSeek首轮融资曝光,估值450亿美元
DeepSeek首轮融资曝光,估值450亿美元据金融时报的最新消息,多家机构目前正寻求领投 DeepSeek 的首轮融资。如果谈判顺利,DeepSeek 在本轮的估值将达到约 450 亿美元。短短几周内,DeepSeek 的估值就从刚开始被爆料的 200 亿美元一路狂飙翻倍。
来自主题: AI资讯
9471 点击 2026-05-06 16:46
 搜索
搜索
据金融时报的最新消息,多家机构目前正寻求领投 DeepSeek 的首轮融资。如果谈判顺利,DeepSeek 在本轮的估值将达到约 450 亿美元。短短几周内,DeepSeek 的估值就从刚开始被爆料的 200 亿美元一路狂飙翻倍。
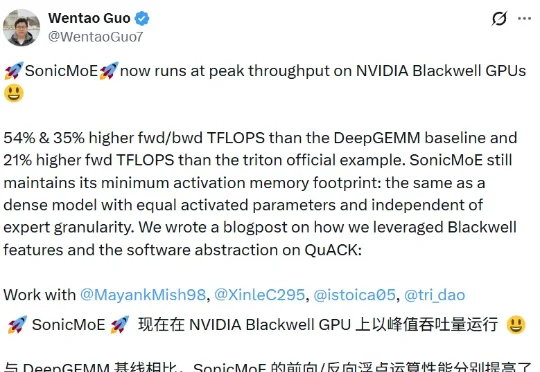
近日,由普林斯顿大学 Tri Dao(FlashAttention 的一作)和加州大学伯克利分校 Ion Stoica 领导的一个联合研究团队也做出了一个超快的索尼克:SonicMoE。据介绍,SonicMoE 能在英伟达 Blackwell GPU 上以峰值吞吐量运行!并且运算性能超过了 DeepSeek 之前开源并引发巨大轰动的 DeepGEMM。

你要是问当今互联网最神秘、最玄学、连量子力学都解释不清的「时空裂缝」在哪里?它不在百慕大,也不在诺兰导演的电影里,而是在你的 DeepSeek、Claude 或者 ChatGPT 正在思考的过程里。
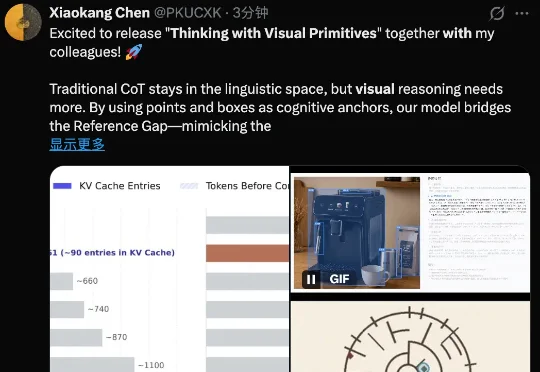
刚刚,DeepSeek 在 Github 上正式发布了多模态模型,公布了背后的技术报告。实打实的新鲜出炉!而且是开创性的推理范式。下面我们就基于 DeepSeek 这篇技术报告,具体看看 DeepSeek、北京大学、清华大学又创造了怎样的奇迹。

就在刚刚, DeepSeek 上线了识图模式,显示正在灰测中。这意味着讨论了一整年的 DeepSeek 多模态能力,终于来了!目前 DeepSeek 网页版和 App 更新后都有可能被灰测到识图模式,APPSO 第一时间给大家进行了实测。

今天上午,DeepSeek V4 发布,直接把这个大模型疯狂更新月推向了最高潮。不过在我翻看 V4 的技术报告的时候,在训练层面看到了一个被大部分人滑过去的名词:Muon 优化器。
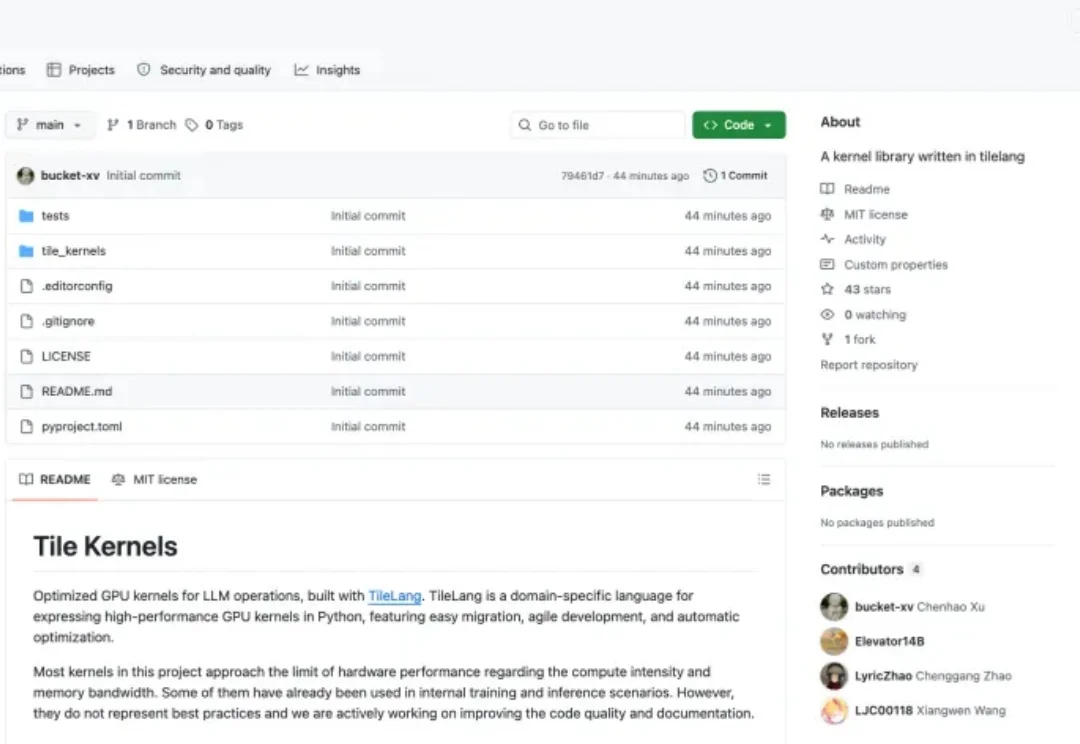
就在刚刚,DeepSeek 的 GitHub 开始了频繁更新,上线开源了一个新的代码库 Tile Kernels,同时并对 DeepEP 代码库进行了更新,上线了 DeepEP V2。距离上次 DeepSeek 悄悄更新 Mega MoE、FP4 Indexer 还不到一周。

大模型人才涌入,帮助智驾厂商突破原有技术框架上限。
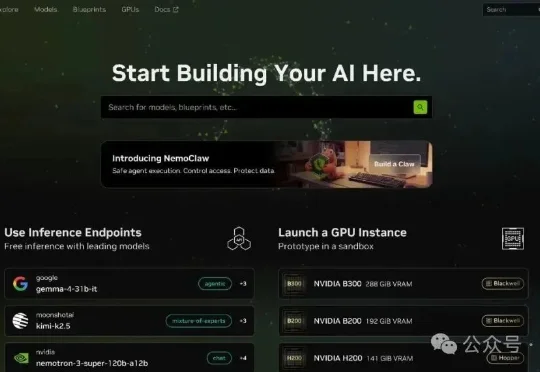
英伟达良心福利!免费领一年顶级大模型订阅,MiniMax / Kimi / DeepSeek 全都能用!NVIDIA 官方平台build.nvidia.com开放了一批"Free Endpoint"模型,注册账号、验证手机号后就能生成一把最长有效期12 个月的 API Key,免费调用几十个当下最火的大模型——不计 Token、无余额限制、无需信用卡。

所有人都在等 DeepSeek,春节来,下周来,还是没来。 一场为了全面「狙击」 DeepSeek,抢夺流量,但是 DeepSeek 都没出现的春节大战,就在一轮又一轮的红包奶茶里轰轰烈烈地结束了。